2.1 计量资料的数据分布与正态性检验
最后更新:2022/04/18
【例2-1】计量资料的数据分布
对数据进行统计分析,统计描述是第一步。
对于计量资料,描述其数据分布,即集中趋势(平均数)和离散趋势(数据的变异程度),通过直方图观察其频数分布,根据其分布特征选择合适的描述性统计量,是统计描述的主要工作。
以体重指数(Body Mass Index,BMI)为例,根据心理学教授Davis(1990)公开的研究数据,使用SPSS 23对该数据进行统计描述的具体过程如下:
1. 建立数据集
本数据可以通过读入的方式,在SPSS中直接打开Excel文件(参见:1.2 SPSS的一般操作与数据集的建立),也可以通过复制等其它方式建立新的SPSS数据集。
数据列表(数据视图)如下所示:
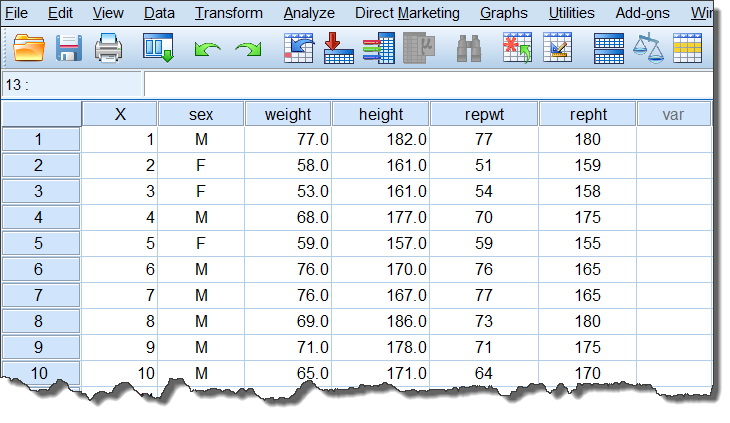
图2-1-1
变量视图如下:

图2-1-2
2. 计算并生成新变量BMI
上述数据集中并不含体重指数BMI,因此要通过已有变量进行计算获得BMI。
BMI的计算公式:$BMI~=~\frac{体重}{身高^2}$,其中,体重的单位为公斤,身高的单位为米。
由于数据集中的身高单位为厘米,所以实际的计算公式为:$BMI=weight/(height/100)^2$,计算过程在SPSS中的操作如下:
点击菜单:Transform => Compute Variable
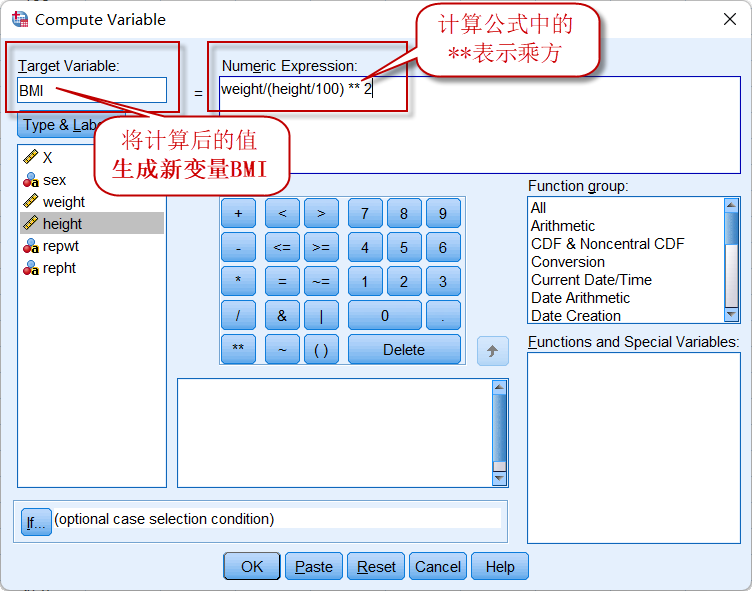
图2-1-3
对话框左上角的Target Variable是将计算结果作为新变量保存时,设置的变量名;
对话框右侧的计算公式中,必须使用已有变量的变量名,公式写书好之后,点击OK就可以在数据集中生成一列新的变量BMI:
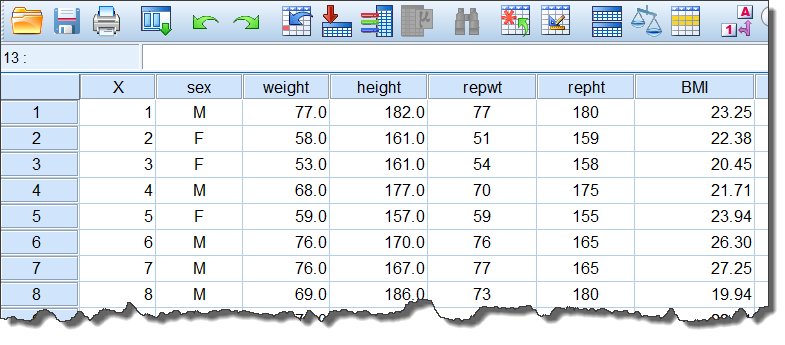
图2-1-4
3. 数据分布的描述性统计量
点击菜单:Analyze => Descriptive Statistics => Frequencies
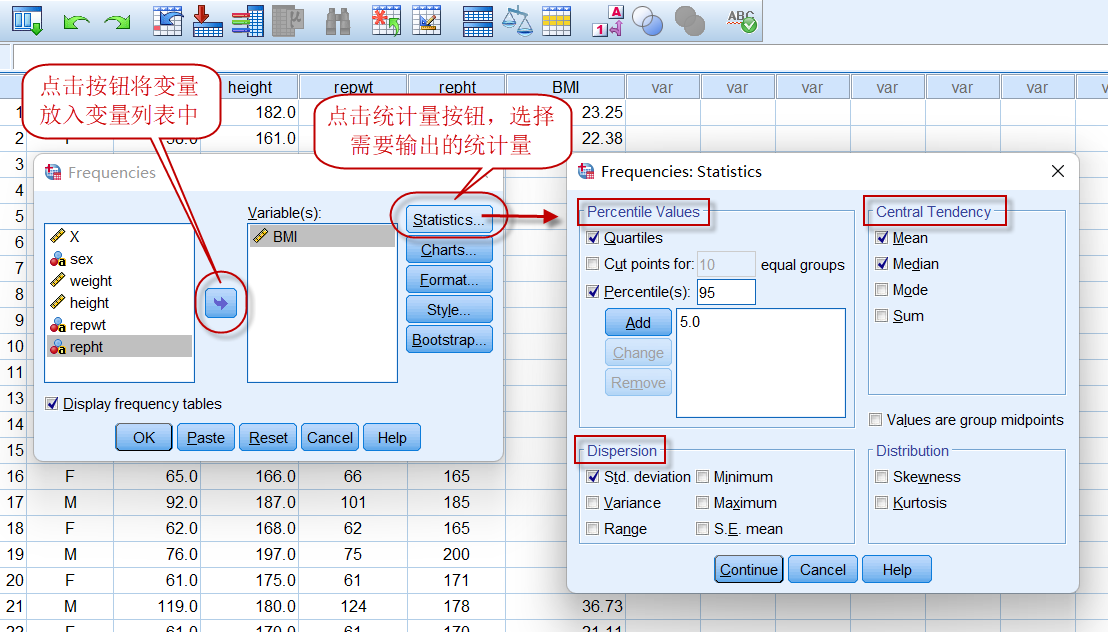
图2-1-5
在Frequencies对话框中,可以将多个需要计算的变量放入Variable(s)(变量列表)中,因本例仅对BMI进行统计描述,故仅放入BMI。
在Frequencies: Statistics对话框中,根据需要选择相应的统计量,其含义如下:
(1)右上角的Central Tendency是集中趋势统计量,包括:
Mean:算术均数
Median:中位数
Mode(众数)和Sum(和)在统计描述中一般不用。
(2)左下角的Dispersion是离散趋势统计量,包括:
Std. deviation:标准差
Variance:方差
Minimum:最小值
Maximum:最大值
Range(极差)和S.E. mean(标准误)在统计描述中一般不用。可能有的国外学术期刊在统计分析时明确要求提供标准误,用于评价样本的抽样误差。
(3)左上角的Percentile Values是百分位数:
Quartiles:四分位数,包括下四分位数Q1(即第25百分位数,P25)、中位数(即第50百分含位数,P50)和上四分位数Q3(即第75百分位数,P75);
如果想计算其它百分位数,可以点击Quartiles下面的Percentile(s)选择,输入需要计算的百分位数并点击【Add】按钮添加(如上图所示)。
全部设置好后,点击【Continue】按钮关闭Frequencies: Statistics对话框,再点击Frequencies对话框的【OK】按钮,即可输出统计结果,如下所示:
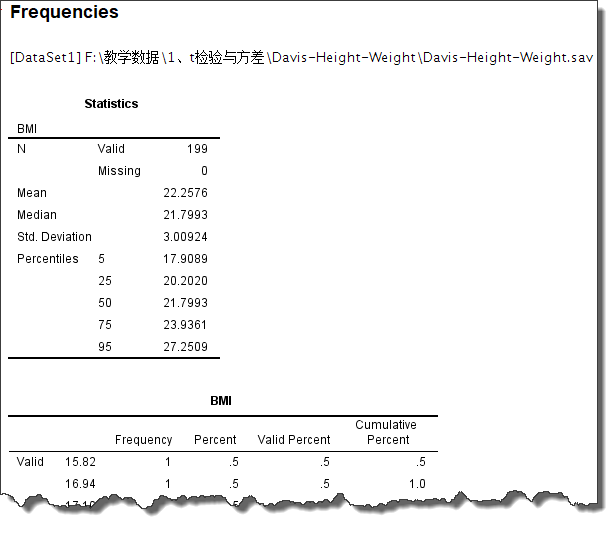
图2-1-6
在Statistics(统计量)表中,就是我们选择的各个统计量的计算结果了。
4. 通过直方图与正态性检验进一步了解数据的分布特征
计量数据的直方图,在SPSS中有多种方法可以获得,比如在图2-1-3中,点击Frequencies对话框中的【Charts】按钮,就可以选择输出直方图:
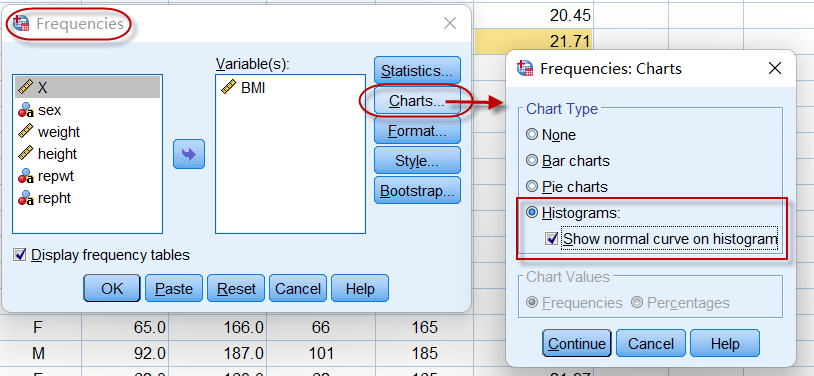
图2-1-7
也可以在进行正态性检验时,一并输出直方图,操作如下:
点击菜单:Analyze => Descriptive Statistics => Explore
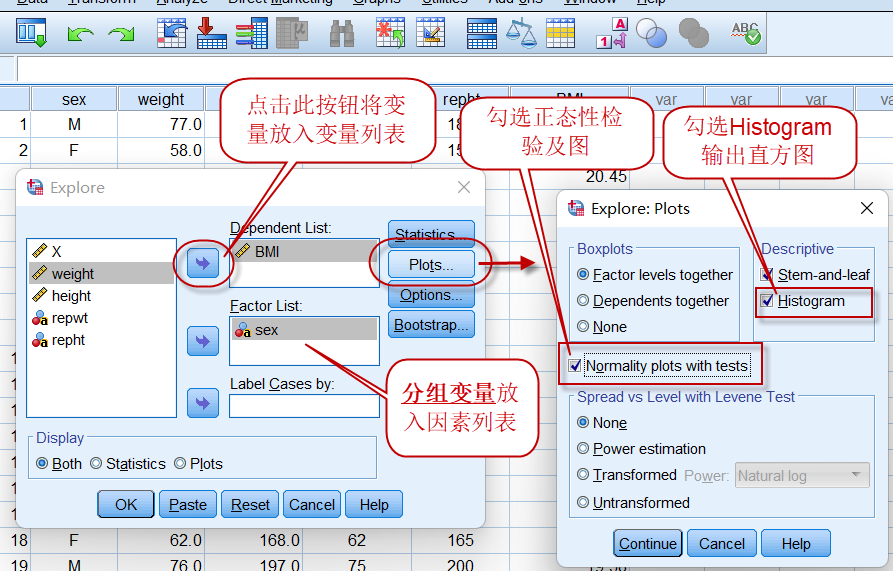
图2-1-8
设置变量及分组因素(本例中为sex,将分别输出男性与女性的正态性检验结果),点击【Plots】按钮,在Expore: Plots对话框中,勾选直方图和正态性检验两个选项(如上图),点击【Continue】=>【OK】,就能输出结果,因为Expore的默认选项我们没有去除,所以输出的结果中内容非常多,截取我们需要的信息如下:
(1)正态性检验的结果
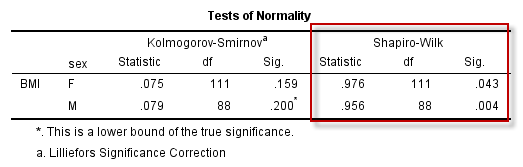
图2-1-9
SPSS中提供了两种正态性检验的方法:
KS(Kolmogorov-Smirnov)检验和W检验(Shapiro-Wilk),一般认为样本量的范围在4~2000时,W检验的检验效能较高,而样本量超过2000时应采用KS检验结果。
本例中总样本量为199,因此选择W检验的结果:
对于Female,P = 0.043 < 0.05,因此拒绝原假设,认为女性的BMI不服从正态分布;同理,认为男性的BMI也不服从正态分布。
(2) 正态Q-Q图(Quantile-Quantile Plot)
正态Q-Q图是直观地检查数据是否服从正态分布的方法,如下图:
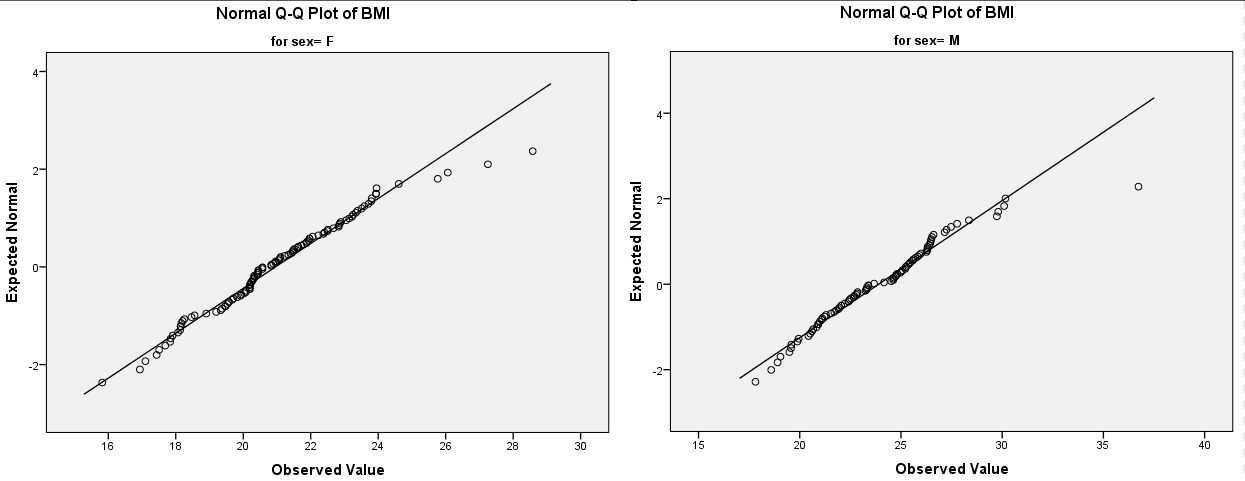
图2-1-10
如果数据呈正态分布,则Q-Q图中的点应位于对角线上。相反,图中的点与对角线的偏差越大,说明数据服从正态分布的可能性就越小。
当然,Q-Q图的方法是一种直观的目视法,通过正态Q-Q图判断数据是否服从正态分布有些主观,但是可以结合正态性检验的结果,对数据的正态性做一个综合判断。
通过正态性检验与正态Q-Q图,我们可以判断:无论哪种性别,BMI都是不服从正态分布的。事实上,从下面的直方图可以看出,男性和女性的BMI都有一点右偏,但是右偏并不严重,所以我们看到的Q-Q图中,大多数的点都在直线上或附近,只有少数离群值(与其它值相比,异常小或异常大的值)脱离对角线较远。
(3)直方图
本例输出的直方图:
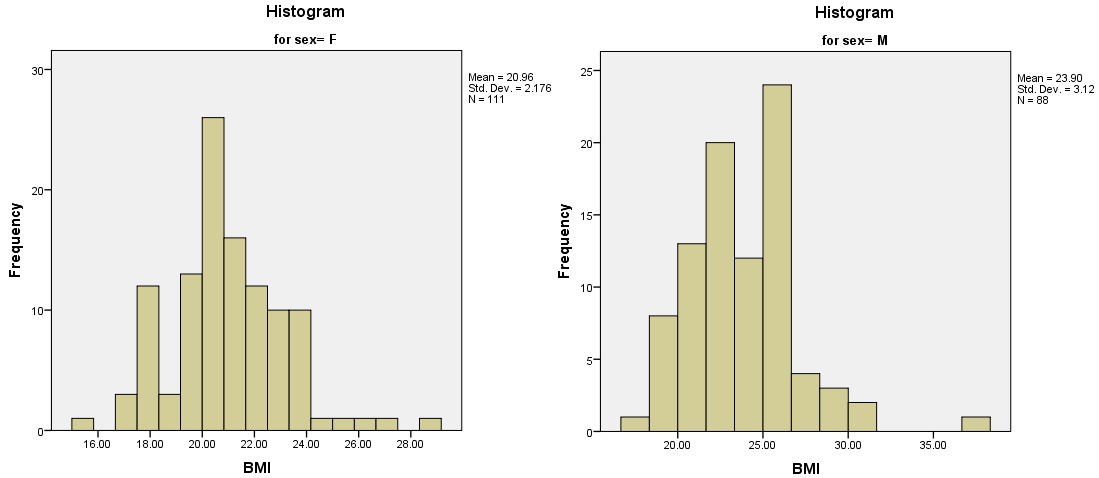
图2-1-11
直方图是观察数据分布最直观的方法,上图显示出BMI的分布:女性的BMI对称性稍差,男性的因为右侧的离群值因而显得比女性的更右偏一些。
(4)根据数据的分布特征,选择适当的描述性统计量
本例中BMI呈右偏态分布,宜选择中位数来描述其集中趋势,选择Q1和Q3来描述其离散趋势;相反的,如果数据服从正态分布,就可以选择算术均数($\bar x$)和标准差(S)来描述这个样本数据。
注意!
如果样本量很大(如下图),正态性检验的方法,几乎总是拒绝原假设,得到数据不服从正态分布的推断。
所以在大样本量的情况下,最好通过直方图或正态Q-Q图直观判断数据分布。
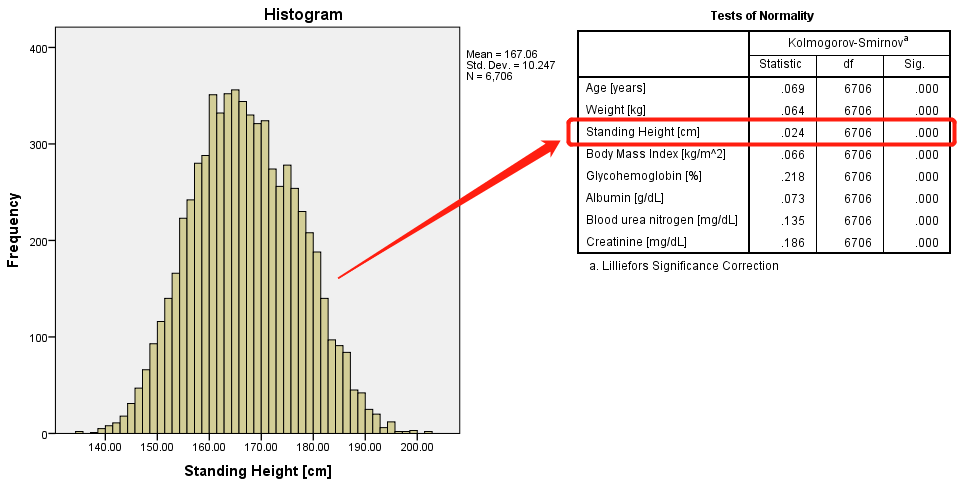
图2-1-12
而在样本量较小的情况下,Shapiro-Wilk正态性检验的检验效能往往较低,如:
在R4.1中模拟生成一个beta分布的数据
dd=rbeta(10000,2,5)
数据分布:
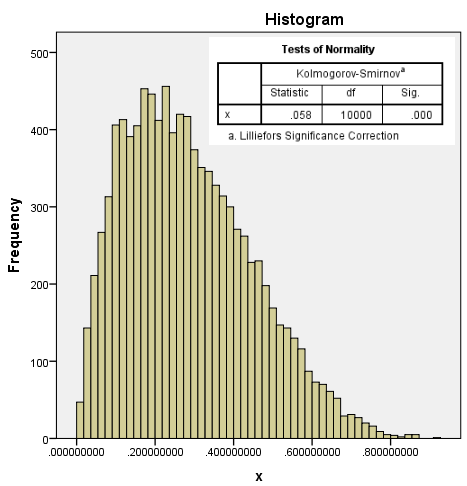
图2-1-13
从中随机抽取50个数据,进行Shapiro-Wilk正态性检验,只有大约50%的样本,能拒绝$H_0$,得到数据不服从正态分布的推论,也就是检验效能约为50%。如果样本量降低到20,针对此数据的检验效能只有不到20%。
所以对于小样本计量资料,除非有比较充分的证据,或者图形方法显示出明显的正态分布的钟型,“分布未知”可能是对其数据分布最好的判断。
5. 数据的分组
上述描述性统计量,如果我们需要对男性和女性分别进行描述,则需要多一步操作:
先点击菜单:Data => Split File
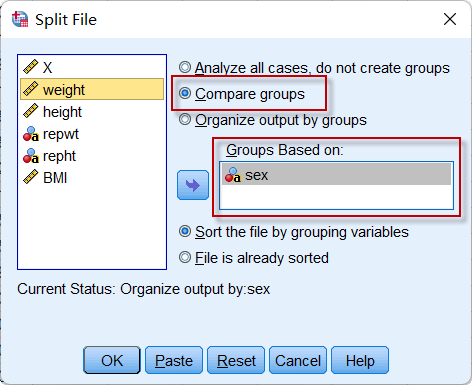
图2-1-14
选择Compare groups选项(其实下面的Organize output by groups也能实现分组输出,但形式不同),并将性别变量(sex)放入分组变量【Groups Based on】中,点击【OK】后,再按照上面的操作,生成描述性统计量,结果如下:
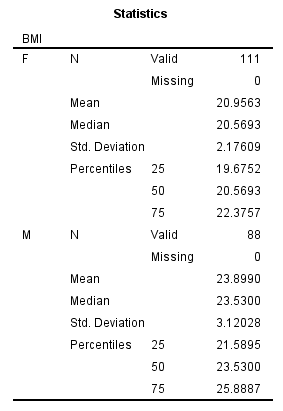
图2-1-15
如果需要取消数据分组统计,选择Split File对话框中的第一个选项并点击【OK】
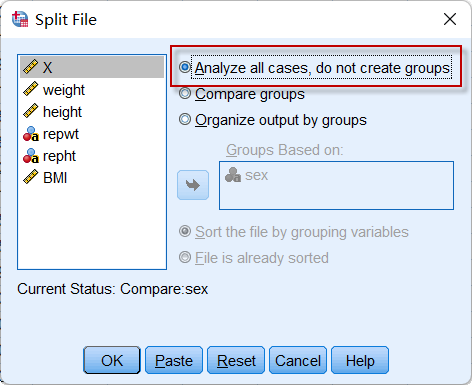
图2-1-16
© By StatX..